Does Google Crawl With HTTP2 Yet?

HTTP2 is a major revision to the HTTP protocol, agreed in 2015. At this stage it has pretty much universal support across web browsers. As HTTP2 supports multiplexing, server push, binary protocols, stream prioritisation and stateful header compression it is, in almost all instances, faster than HTTP1.1 and so implementing it can provide a relative ‘free’ speed boost to a site. But, how does Google handle HTTP2? We thought we’d find out.
The History
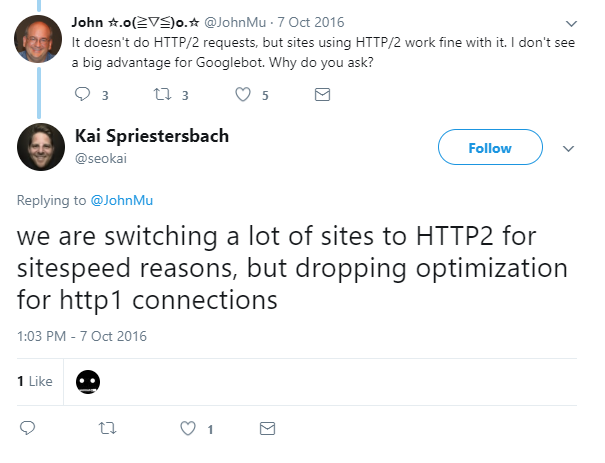
As HTTP2 is backwards compatible – if a browser doesn’t support HTTP2, HTTP1.1 is used instead – Google could read pages on HTTP2 sites the very first day the specification was built. Yet this backwards compatibility actually makes it difficult to tell whether Google is actually using HTTP2 or not. Mueller confirmed in 2016 that Googlebot wasn’t using HTTP2 yet:
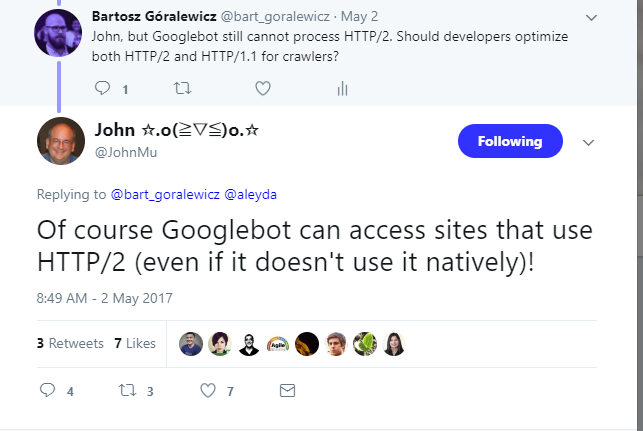
A year later, in 2017, Bartoz asked the same question and found that googlebot still wasn’t using HTTP2:
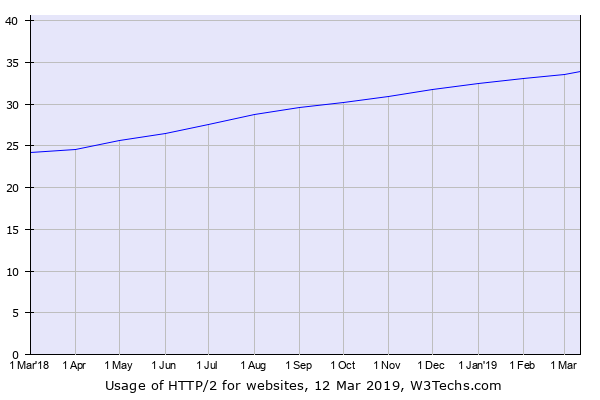
Two years later, much has changed, HTTP2 is now used by over a third of websites and that figure is growing by about 10% YoY:
So, we thought we’d revisit the question. The setup was a little time consuming, but simple. We set up an Apache server with HTTPS and then HTTP2 support and made sure that Google could crawl the page normally:
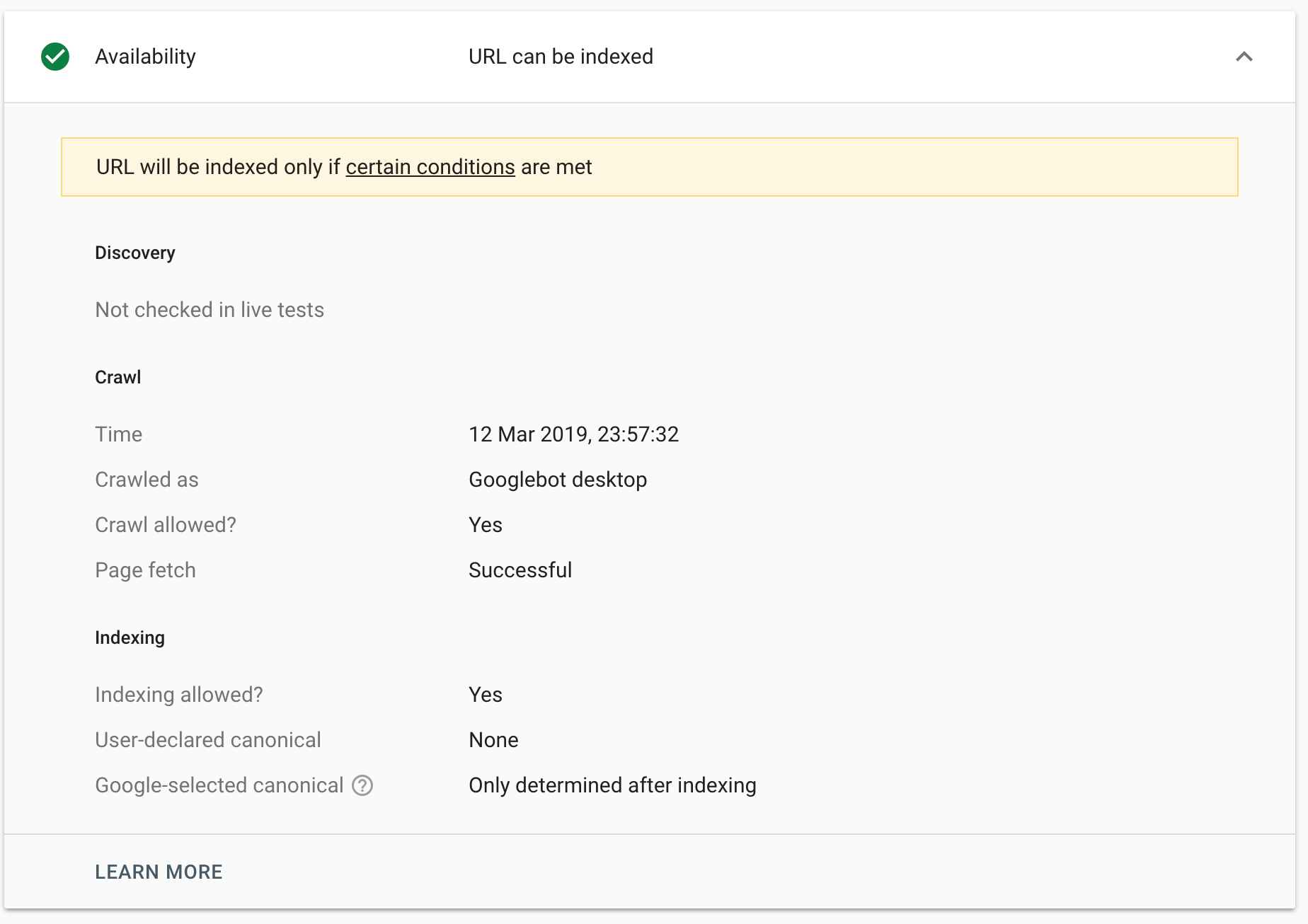
Once we knew that was working, we edited the .htaccess file to block all http1.* traffic:

This time, when we requested Google recrawl the page, we received a crawl anomaly:
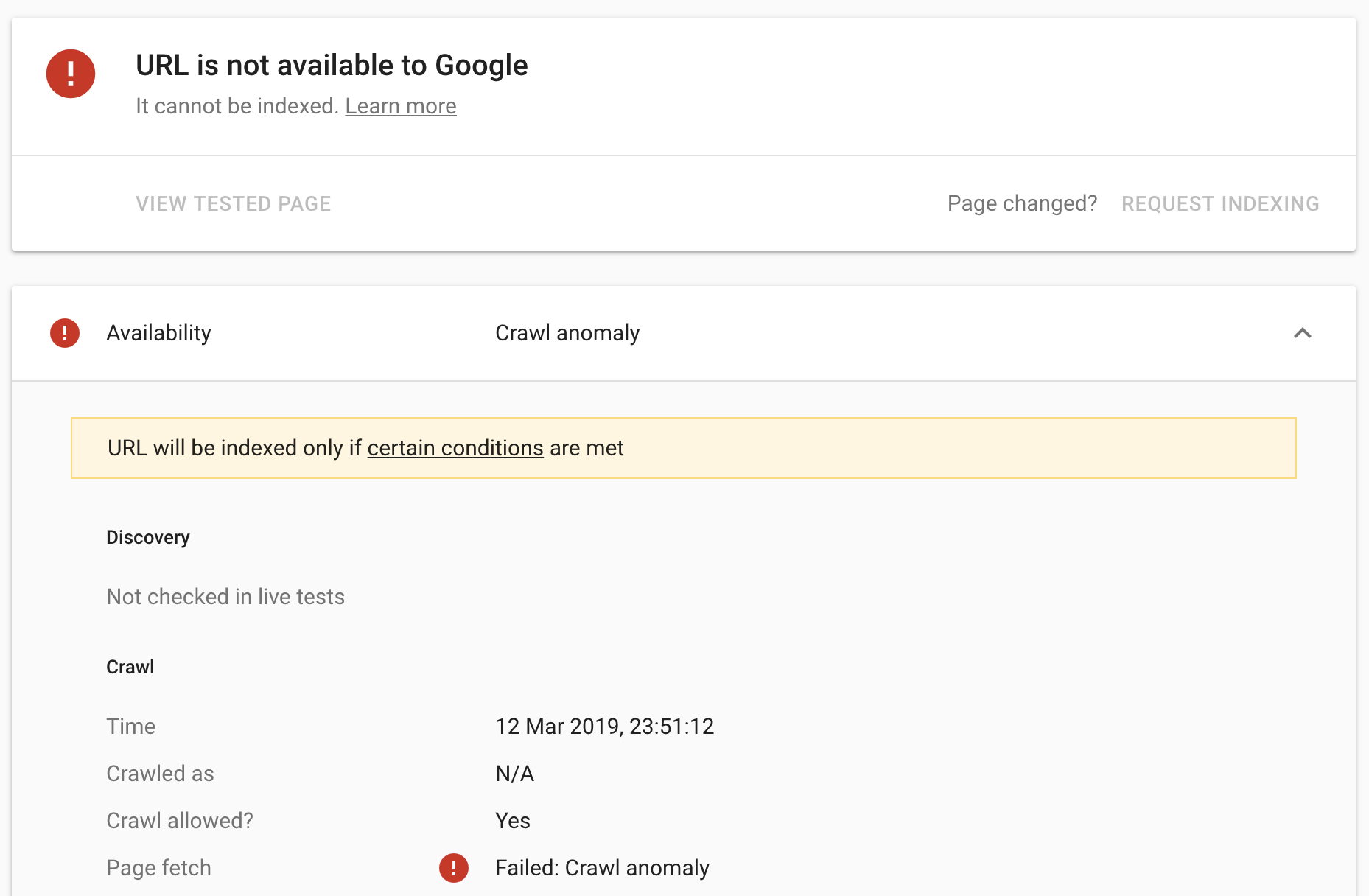
..and so no, googlebot still, somehow, does not support HTTP2. We wanted to see how Google would render the page as well, though. The assumption was that whilst Googlebot did not support HTTP2, WRS/Caffeine is based on Chrome 41, and Chrome 41 supports HTTP2, so, therefore, WRS should too. As a result, we changed the .htaccess file to, instead, redirect all HTTP 1.1 traffic to another test page:

We then used PageSpeed insights to see how Google would render the page:
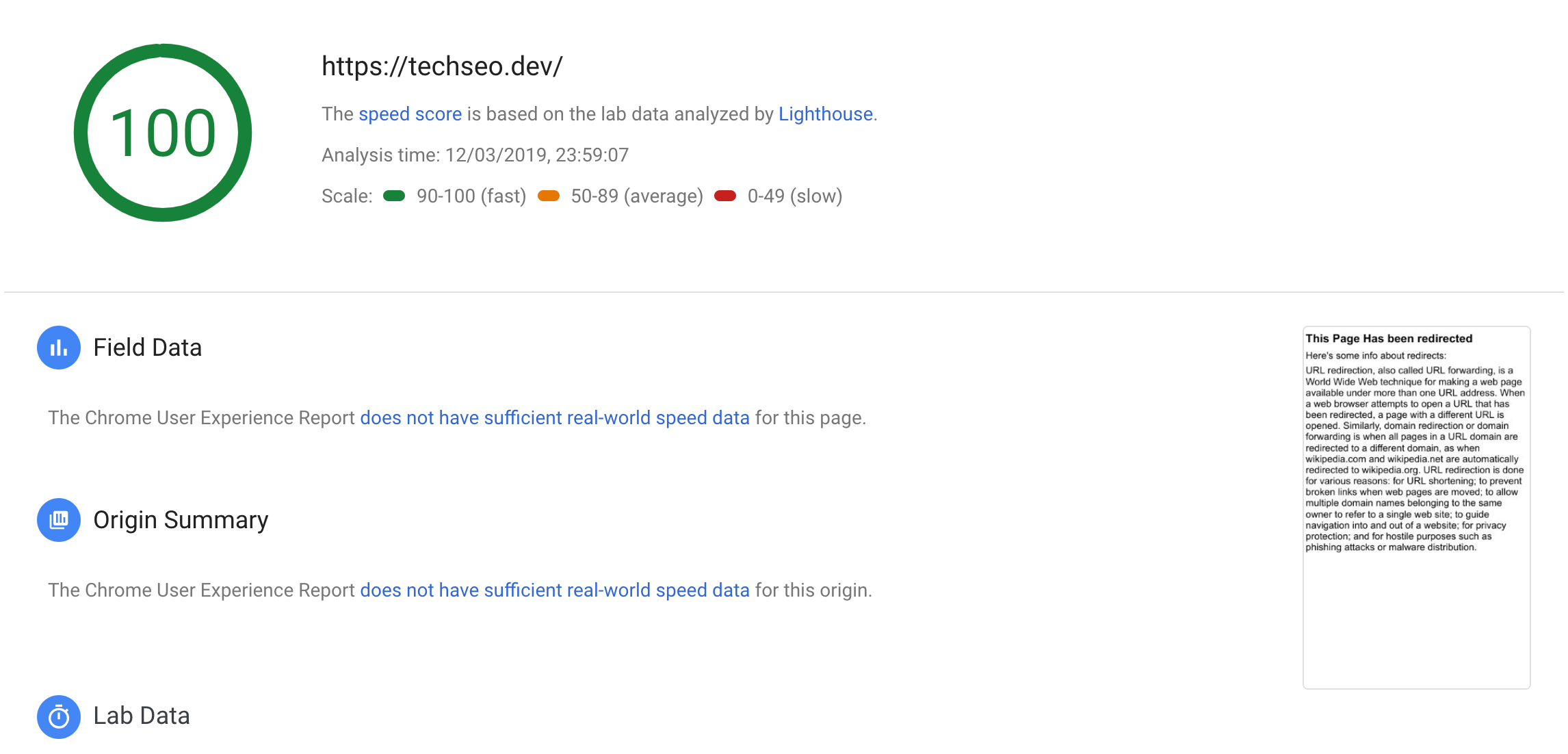
You may just about notice the preview in the bottom left is of a page with the headline ‘This page has been redirected’ – it loaded test.html rather than the homepage! So, for whatever reason, we must presume, that Google has hobbled WRS so that it always pulls the HTTP1.1 version of a page, which, in 99.999999% of cases would be identical to the HTTP2 version of the page.
Why does this matter?
This is interesting for two reasons:
1) It implies a very interesting way to cloak that I’ve not heard people talk about before. Internet Explorer has supported HTTP2 since 2013, whilst Firefox, Safari and Chrome have each had support since 2015. If you set certain content to only show for users with HTTP1.1 connections, as modern browsers all support HTTP2, effectively zero users would see it, but Google would. As with all cloaking, I don’t actually recommend this – and Google could add HTTP2 support at any time – but as ways of cloaking go, it would be difficult to detect as, effectively, nobody’s looking for it right now.
2) Due to HTTP2’s multiplexing abilities, there are several site speed recommendations that are different for HTTP1.1 than HTTP2 including, for example, spriting. Now that we know Google is not using HTTP2 even when your server supports it, by optimising your page for speed based on users using HTTP2 you might actually be slowing down the speed at which Google (still using HTTP1.1) crawls the page. Whilst Google’s tight-lipped on what mechanism, exactly, they use to measure site speed, the page load speed that googlebot itself finds will, of course, go to determining crawl budget. So if you’re really caring about crawl budget and are about to move to HTTP2 then you’ve got an interesting problem. This is simply one of those cases where what’s best for Google is not what’s best for the user. As such, there’s a reasonable case to be made that you shouldn’t prioritise, or potentially even bother implementing, any site speed changes that are different for HTTP1.1 than HTTP2 when moving to HTTP2 – at least until Google starts crawling with HTTP2 support… or you could combine both approaches and change the way you’re delivering CSS, icons etc based on the HTTP version that’s supported by the requested user, which is a lot of extra work, but technically optimal. That is, as we all know, the best kind of optimal.
Mostly, it’s just interesting though.