Content and digital PR takeaways from BrightonSEO July 2021
This summer’s Brighton SEO 2021 conference was packed with impressive speakers from a range of professions in the SEO industry, including our very own Laura D’Amato and Giacomo Zecchini.
Members of the Verve team highlighted a number of interesting talks that took place over the two days and reported back with some of their favourite takeaways of the sessions.
Making headlines: Pitching tips and debunking myths from a former journalist
At the ideation stage, think like a journalist would and try to figure out how you could reach a headline or story that would evoke certain emotions such as shock, anger, sadness, happiness, or outrage.
Your subject line really is absolutely key as it is the only factor that will decide whether a journalist would open your email or not.
Don’t do a click-bait headline. Journalists see through it and will delete it ASAP.
Be specific. ‘Manchester is the most popular city for shopping’ rather than ‘The 10 best cities for shopping in the UK’. Journalists want to know immediately what the story is.
Front-load keywords in your subject line – the most important keywords at the front.
When prospecting and refining your pitch, check recent articles by the journalist and see when they were published to gauge when to send your pitch. Journalists work shifts, so 8am Monday-Friday might not be the only pitching-time option.
Speakers: Laura D’Amato, Surena Chande, Jon Buchan, Chris Czermak, Sarah Fleming, Jasmine Granton, Louise Parker, Laura Wilson.
Favourite takeaways:
When going out with a reactive piece of content, always get a second pair of eyes (preferably the client) beforehand.
Having a diverse set of skills and experiences on your team is great for coming up with ideas, for checking campaigns, and for ensuring that what you put out is ethical.
Be honest and believe in your abilities with brands. It will make them trust you a lot more.
The speakers had different opinions about whether you need to put out a campaign or not. At the end of the day, it depends on your or your client’s expectations. As long as this is clearly communicated and that you agree with what you want the results to be, you can choose how to get there.
Verve’s take on it is that big campaigns allow us to reach out to a large panel of journalists with in-depth research and therefore get the attention of top-tier publications. However, we always like to mix this with a more reactive approach to target relevant publications for the client.
As long as your content is relevant and resonates with your target audience, the format is not the most important.
Your content needs to be suitable for social media too as it’s a big part of journalists’ KPIs.
Diversity and Inclusion in Marketing, One Year On – Why Has Nothing Changed?
Speaker: Azeem Ahmad, Digital Marketing Lead at Azeem Digital
Favourite takeaways:
Companies should ensure every leadership bonus is tied to D&I initiatives – if POC/women aren’t being paid fairly, neither should the leadership.
Start to measure and publicly release detailed yearly diversity data.
Introduce wage equity schemes to ensure women and POC are being paid on par with white counterparts.
Looking back at 2020:
8% average POC speaking representative at selected conferences. All were men.
6 in 10 believed their identity or ethnic background has affected their career opportunities.
58% said they were either unsure or disagreed that their workplace actively tried to address the diversity gap between POC/white staff, and 43% believed their organisation doesn’t have an inclusive culture.
2021: Why has nothing changed?
One in six fear they would lose their job if they got terms around race and ethnicity wrong, while 30% felt it would lead to disciplinaries.
Workers are more confident talking about death (38%) than race and ethnicity (29%) in the workplace.
Speaker: Laura Wilson, Digital PR Manager at Shout Bravo
Favourite takeaways:
Campaign…
Make sure it has different angles to go out with, to different journalists, different publications, and fits different niches. Don’t limit what you can achieve with your campaign.
Have on hand a rich variety of different assets: data, visuals, case studies, expert comments, and (if it’s relevant for them to provide them) client comments.
Writing a press release…
Personalise your pitch to the journalist. Use their name. Is it really relevant to them? Have they written about this subject before? What do they normally feature in the way of assets or case studies?
Cater what you include in your email according to what the publication typically covers. National newspapers tend to like gender breakdowns in data. Niche industry publications will want to talk about data relevant to the industry.
Use a subject line relevant to that publication and make sure it is effective. There are lots of tools out there that can analyse and score your subject line on its effectiveness. Try things out and experiment to see what works best.
Write according to the language and tone you see in the target publication: for example, do they write in a sensationalist tone or more factual?
Brief press releases are better for bigger publications. They are busier and the brief needs to be more to the point. Include all the key information that they need. Detailed press releases are better for niche publications. Detailed releases will be really relevant to them so they can have lots of detail.
Big national newspapers like case studies as it provides a first-hand experience of the subject in your release. Consider focusing your pitch around this case study if it’s strong enough. Otherwise, you can just mention that you have one on hand.
Including expert commentary – whether external or client – makes a journalist’s job easier. They won’t have to search it out themselves if they need it.
The more you provide, the less a journalist has to do. It’s easier for them to take all your assets and get a story live if they don’t have to keep referring back to you.
Great accessibility is also great UX. Great UX has long-term SEO benefits for your brand and builds brand loyalty. If your website is accessible to everyone, it makes sense that more people will come back to use it and recommend it.
There are various kinds of disabilities you need to be aware of when building your website. These include not only sensory, cognitive, or motor, but situational, temporary, and socioeconomic. A temporary disability might be that you’re in a space where you can’t listen to a video out loud and need subtitles. Temporary includes carpal tunnel syndrome or a concussion. Socio-economic disabilities might include poor wifi, which impacts load speed and limits what a user can access.
There are different things you need to consider to make your website more accessible. The main ones highlighted in this talk are: improving your site’s colour contrast; making images accessible (e.g. with alt text); ensuring accessible navigation (e.g. making your website conveniently accessible with just a keyboard); and using the right tone of voice (e.g. using plain English).
There are free tools available online to assess your website’s current accessibility and help you to improve it. One example is WebAIM’s contrast checker.
In the UK alone, £17.1 billion is lost every year due to inaccessible websites. You are also legally obliged to make your website accessible.
How to devise a content strategy following a content audit
Speaker: Jess Peace, Senior Content Producer at NeoMam Studios
Favourite takeaways:
There’s no one-size-fits-all approach to content marketing, particularly where your target audience is concerned. Your business goals should highlight areas of focus, which will help to set your content strategy’s priorities.
Before trying to define what content you want to create, first define the audience that it is for. This will help to make the content more relevant and valuable for them, and increase the likelihood of greater engagement and more conversions. To do this, ask questions like: Who do you want to reach? Are you looking to expand your audience or target a new one? What does your audience care about?
Try applying the ‘snog-marry-avoid’ framework when combing through existing pages during a content audit. It can be defined like this:
Snog: content that works well in meeting KPIs but could be working harder Marry: content that works really well in meeting your KPIs and is a prime example of the kind of content that you should be creating more of Avoid: content that doesn’t really hold any benefit, for example, it drives no traffic, has low engagement and/or is outdated
The importance of consumption for creativity: we work in an inspiring industry full of creative case studies, but also pay attention to what’s outside of the industry, and outside of your realms of interest in the form of blogs, podcasts, artwork, newsletters, TikTok, inspiring people, Reddit, etc.
When your only goal is earning links, it can be easy to forget about core PR values, like looking after your client’s brand.
At the ideation stage…
Make sure you have a tight methodology and strong data:
In an age where consumer trust in the media is low, we owe it to the public to provide the correct information.
Weak and untrustworthy data will negatively impact your relationship with journalists.
It upholds certain digital PR standards. It’s not ethical or good for the industry as a whole to provide false data.
Consider the ethical implications and ask yourself:
Could the campaign be harmful, e.g. add to harmful stereotypes or upset a group of people?
Are there opportunities for a journalist to take your story and turn it into something harmful? Is it harming a conversation taking place in culture and could it take the media’s attention away from more important conversations in that space?
Is it inclusive? Are the designs thoughtful and inclusive as well? Not only does inclusive design reflect well on the brand and include more people in its audience, but gives us some power in the media to enact real change in representation.
Think about brand guardianship, too:
Be honest with your client. They need to be aware of their limitations when it comes to the type of content they can put out. A campaign can’t be hypocritical. Where are they an authority and where are they not?
You’ve been trusted with their brand. Think about how you communicate with journalists on their behalf and prevent any backlash or negative attention.
Interested in our content marketing and digital PR services? Get in touch.
outREACH Workshop Video 3 – Measuring the Quality of Links
This is the third and final video from our free outREACH workshop. This was a series of workshops teaching actionable tips and techniques that will enhance your creative content and link-building strategy.
In this third part of the series, James Finlayson, Head of Strategy, discusses different methods for measuring the quality of your outreach efforts. He also talks about history of updates and how this has impacted the way we look at links.
If you haven’t already seen the first in the series, feel free to follow this link and check out Lisa Myers, the CEO and Founder of Verve Search, as she goes through the concept and ideation process of creative campaigns. You can also see Alex Cassidy’s presentation here to learn more about our team’s outreach strategy.
Join us for our next event. On 12th June we are hosting outREACH Online Conference which is a fantastic opportunity for you, or members of your team to hear from the best SEO’s, link-developers, content creators and marketers in the industry including marketing wizard Rand Fishkin, Shannon McGuirk (Aira), Carrie Rose (Rise at Seven), our very own Lisa Myers and many many more. We hope that you’ll be able to join us for this event.
If you have any questions about this content or outREACH Online please contact us at [email protected].
Campaign Spotlight – Crep Check
Starting this month, we will be sharing with you an example of a campaign which has delivered amazing results for a client over the course of the previous month.
This month, we produced Crep Check for Farfetch, a luxury fashion retailer. The campaign looks at the most valuable trainers currently on the market, as well as those that have seen their value skyrocket since their initial release.
We teamed up with Stadium Goods to provide a definitive breakdown of the most valuable and appreciative trainers in modern times, and an explanation as to why so many of these shoes have become worth such vast sums of money.
Costing £22,763, The high-top ‘Jasper’ sneaker from the Kanye West x Louis Vuitton line are the most valuable on the market. Released in 2009, the shoes designed by West himself have increased by more than 2500%. They were initially available in three colourways but the pink and grey version is the most coveted.
We found that Nike’s What the Dunk trainers had the biggest value increase. Released in 2007 at £91, they were designed as a patchwork of previous patterns, colours and materials used in old Nike SB models. Today, they are worth £3,793, an increase of over 4000%.
We took inspiration for the campaign from high-profile trainer auctions and one-off celebrity releases, which have been sold for tens of thousands of pounds. The international news interest these stories generate inspired us to create a definitive list using data provided by one of Farfetch’s key brands.
We also liked the idea of showcasing trainers as alternative investments, a concept we previously explored with coins and toy cars. Lifestyle, fashion, and money journalists love to follow the most recent collectable trends and valuations in fashion.
Our designs took inspiration from ‘sneaker walls’, similar to those found in Stadium Goods’ stores in New York and Los Angeles. We also used price tags to show the rank number, making the campaign feel more like a high-end fashion index. We then researched each shoe using Stadium Goods’ index to provide some context to their value increase.
‘Crep Check’ launched on the 26th June, and to date, our outreach team have delivered 98 links totalling 3367 LinkScore (Verve’s own tool using a combination of metrics to measure the value of links). We were also able to build links in seven different countries.
Our outreach coincided with an auction of the world’s rarest trainers in New York set up by Sotheby’s and Stadium Goods. This included one of the first-ever shoes made by Nike in 1972, which sold for £350,000. The interest in this auction meant journalists were receptive to a report about the subject to inform their story.
It also coincided with a PR storm involving Nike removing a limited-edition shoe from retail following complaints about the use of the ‘Betsy Ross’ flag, which has since been associated with white supremacy after its use as the original US flag.
Both stories helped us to get linked coverage for the client in Business Insider, CNBC, GQ, Houston Chronicle, Yahoo Finance, AD (Netherlands’ second-largest newspaper) and CNN’s Style section. In addition, the BBC’s Newsround team wrote an article about the world’s most valuable trainers using the campaign data.
My First Month in The SEO World
May has been an interesting month in my life. After a few months of job hunting, I was given the cool opportunity to become part of the Verve SEO team. I joined Verve Search at the beginning of May and officially became an SEO newbie.
Before I started here, my only encounter with SEO was a 4-month internship I did with a digital marketing agency, where I was mainly writing content and slowly getting introduced to SEO. For that reason, this opportunity at Verve Search has been a real, eye-opening, and captivating experience. I had the chance of meeting amazing people that made the beginning of my career so much easier and smooth. I feel lucky to have such a cool mentor to guide me through this new path, and to be surrounded by this refreshing work environment.
In this article, I will summarise the main things I learned during my first month as an SEO Executive.
Lesson 1: Wasn’t SEO just spamming links around?
Before I started working on SEO, I had this idea that SEO basically meant throwing links around every blog, directory, or web page you could find, and by doing this, you would magically rank better. Well, that is not even close to being true!
The truth is, one of the first things I learned here was that backlink quality is essential to improve your rankings. Ideally, you should focus at ensuring your external links come from relevant and high authority domains.
A high quality backlink comes from a site that will make search engines trust your website to be one of the best results they can give to the searcher to answer their query.
Lesson 2: White-Hat SEO is the way to go.
In SEO (like in most things in life), there is a proper way to do things, and a sketchy way to do things. White-Hat SEO refers to the cleanest and most honest way to improve a website’s visibility.
Why is this the better way? Well, because when you break the rules Google does not like it and tends to penalise your site, which can be very harmful, and could take you a long time to recover from.
White-Hat means following Google guidelines, to provide the searcher, with the best results. On the other hand, Black-Hat SEO, can be anything that you think might increase your rankings but does not follow Google guidelines. For example, stuffing your content with similar keywords, hoping to rank better in the SERP! Google is too smart for this mate! It probably won’t work!
Lesson 3: SEO is a world of constant change.
Google is constantly changing and developing new algorithms, and better ways to provide the best search engine service. They come up with algorithm updates and major changes all the time (and for some reason they name most of them after cute animals). These sudden updates call for SEOs to be in constant alert for news and tools that could harm or help our websites. We need to be ready to inform and act right away, and the best way to do this is to keep track of all the latest SEO updates and news and to carefully monitor your client’s organic performance.
Lesson 4: SEO and content go together!
Content Marketing plays a huge role in SEO. Content marketing and SEO are partners in crime, they go together like avocados and toast! I see it as simple as this: there is simply no SEO without content, SEO needs content, and content needs SEO.
In my case, content was pretty important since day one. My first main task when I started, was to carry out extensive keyword research. This helped me understand how important the on-site content of a website is, and how much effort actually goes into it.
Lesson 5: Practice, practice, and practice.
These past few weeks I realised how important it is to learn by doing in this industry. There are so many tools to use for different purposes and analysis, and the best way to get your head around it is to jump straight into using them.
At the very beginning, the most frustrating part for me was trying to master every step I was doing, without really having a full understanding of the theory behind it. Nonetheless, this is something that came with time, and it was definitely better that way. It was very satisfactory to slowly learn what the data meant, while at the same time getting to experiment with the tools and materials available to me.
SEO is something you want to learn less by reading, and more by getting your hands into it. Of course, having the proper reading material at hand is always helpful, and learning with the SEO theory from the start is just fine too, but in my experience, it is definitely faster and easier to put the theories to work, play around with the tools at your disposition, and experiment as much as you can.
And that’s a wrap!
4 Things You Never Knew About Sitemap Submissions
Whenever a sitemap changes it’s important to notify Google and Bing of the change by pinging <searchengine_URL>ping?sitemap=sitemap_url . Whilst these URLs are meant for bots, they do return an actual html page. When you look at Google’s responses though, you’ll notice four interesting facts:
1. Google is Tracking Views of the Page
It’s fair to say that 99.9% of page loads for the URLs are by automated systems that do not run javascript. It’s interesting, and surprising, then that Google includes the old GA script within the code:
For reference, that UA-code appears to be a property within the same account as Google’s Search Console, but not part of the actual Google Search Console property (UA-1800-36).
2. Google.com still refers to Webmaster Tools
If you load up google.com/ping?sitemap=example.com you’ll find that the page’s title is:
3. Google shows a different response for different languages
If you load up non-English Google TLDs you start to see that Google’s taken the time to translate the text into the primary language that TLD targets. For example, here’s the response on google.fr:
and here’s the response on google.de:
Each language gets its own translation of the text…. except for google.es:
I guess the google.es sitemap country-manager was out the day they wrote the translations! In any case, it’s surprising that they bothered to create all these translations for a page that, I would imagine, is very rarely seen by a human.
4. Google makes the weirdest grammar change
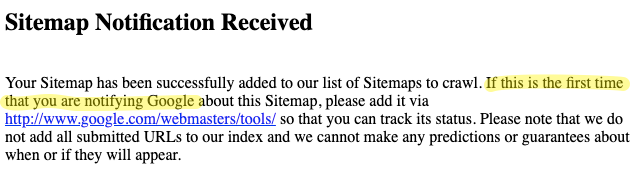
If you load up the the .co.uk, .ie, .co.za or any ‘international’ English version of Google’s sitemap ping URL you’ll find this message:
(we’ve added the highlighting)
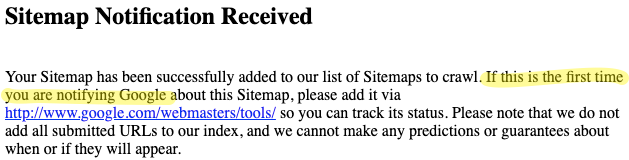
If, however, you load up the .com you receive this:
The ‘that’ in the second sentence disappears.
Why would Google do any of these things? Maybe it just doesn’t care about updating these. Maybe all of the international English-language versions share a single ‘international English’ text and, when someone last updated it, they forgot to update the .com version. Here’s the more interesting question, though. If the ping URL’s frontend is different for each Google TLD, then, does that mean the backend could be different – maybe feeding into their different indexes? Does which Google you ping make any difference? Should you be pinging your ‘local’ Google rather than just the .com?
We pinged our test site about 40 times from various TLDs to see, through our log files, if Google was visiting from different IP addresses when you pinged from a different TLD. It wasn’t. Next, we reached out to John Mueller to see what he had to say:
I’d use the officially documented ping URL. Others might work, or might not — the documented one is the one we officially support.
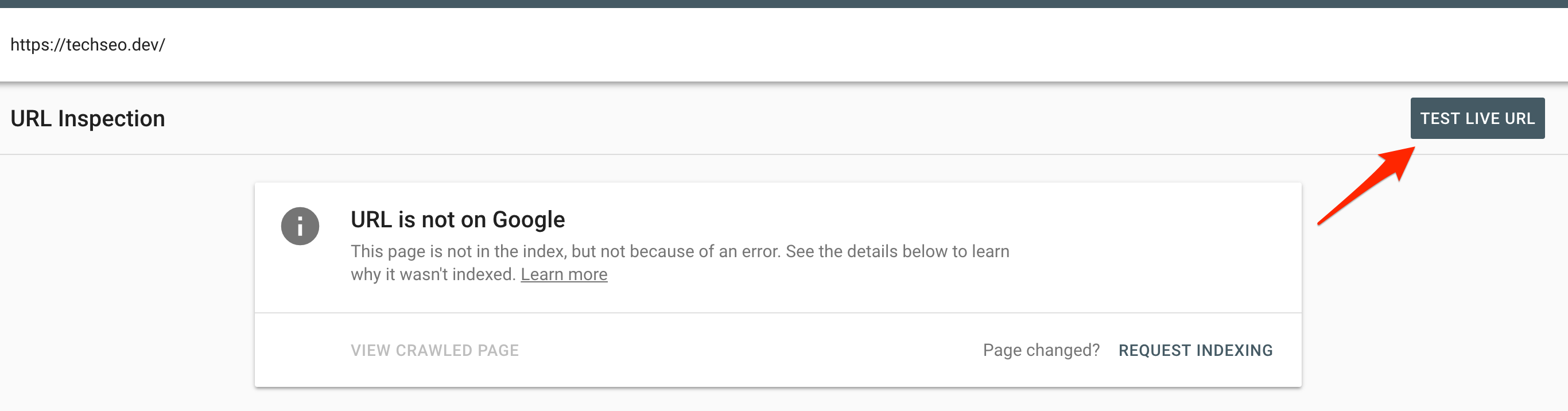
What’s The Limit On Google’s Live Inspection Tool?
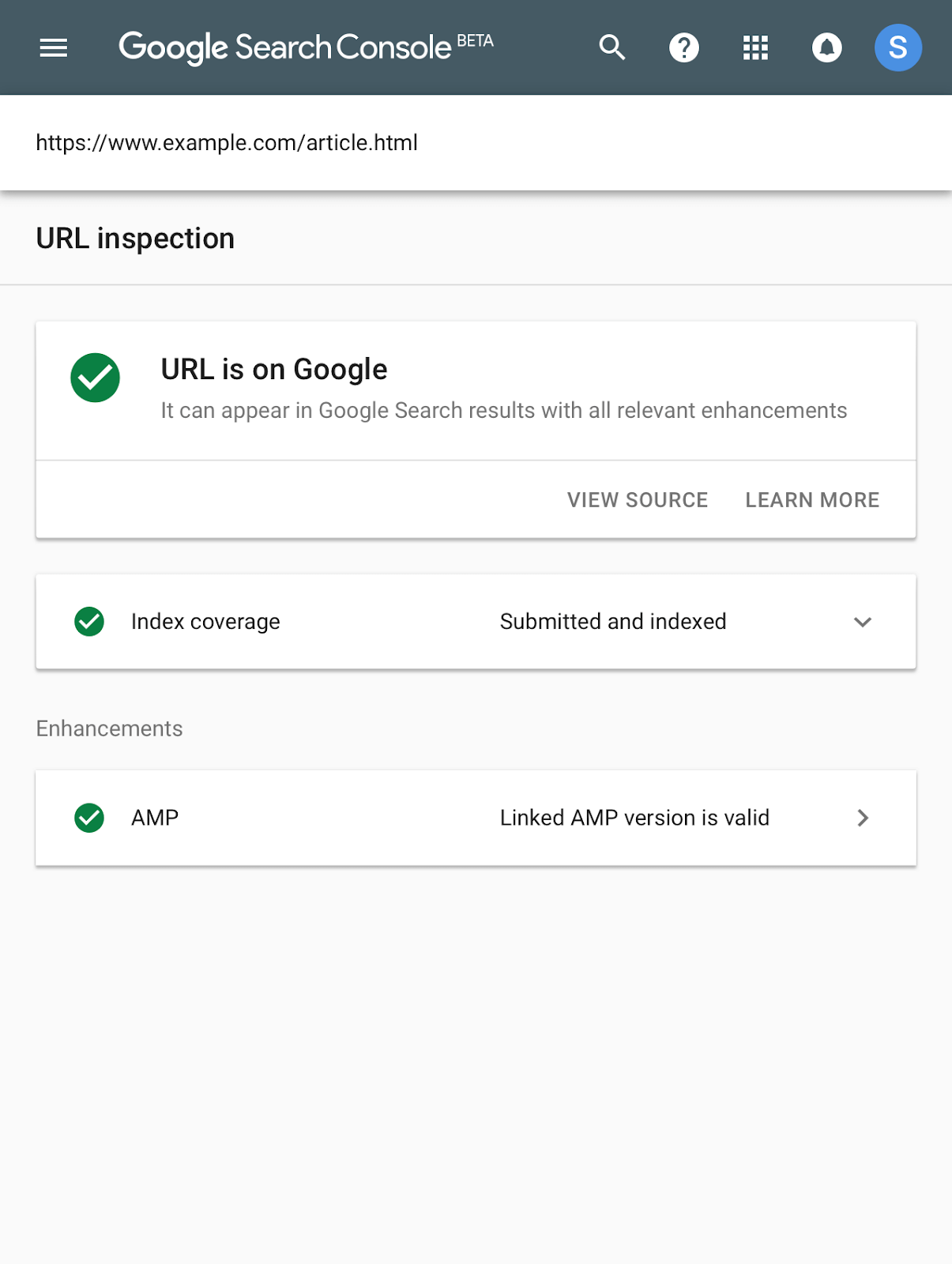
Last year Google launched the beta of the new Google Search Console, but when it first launched it was pretty empty. By June they had added one of the features I now use most often in it, the URL Inspection tool. It allows you to quickly see details as to how Google’s crawling, indexing and serving a page, request that Google pulls a ‘live’ version of the page and request that it’s (re)indexed:
The Live Inspection Tool will soon replace the ‘fetch as Google’ functionality found in the old Search Console and so it’s worth considering how moving to the new version might limit us.
The old fetch and render used to be limited to 10 fetches a month – and had a clear label on it allowing the user to know exactly how many fetches they had remaining. This label disappeared in February last year, but the actual limit remained:
Yes, there are still limits. I’d really aim to use the more scalable approaches (like having a crawlable site, sitemaps, etc) instead of trying to fudge-force indexing manually.
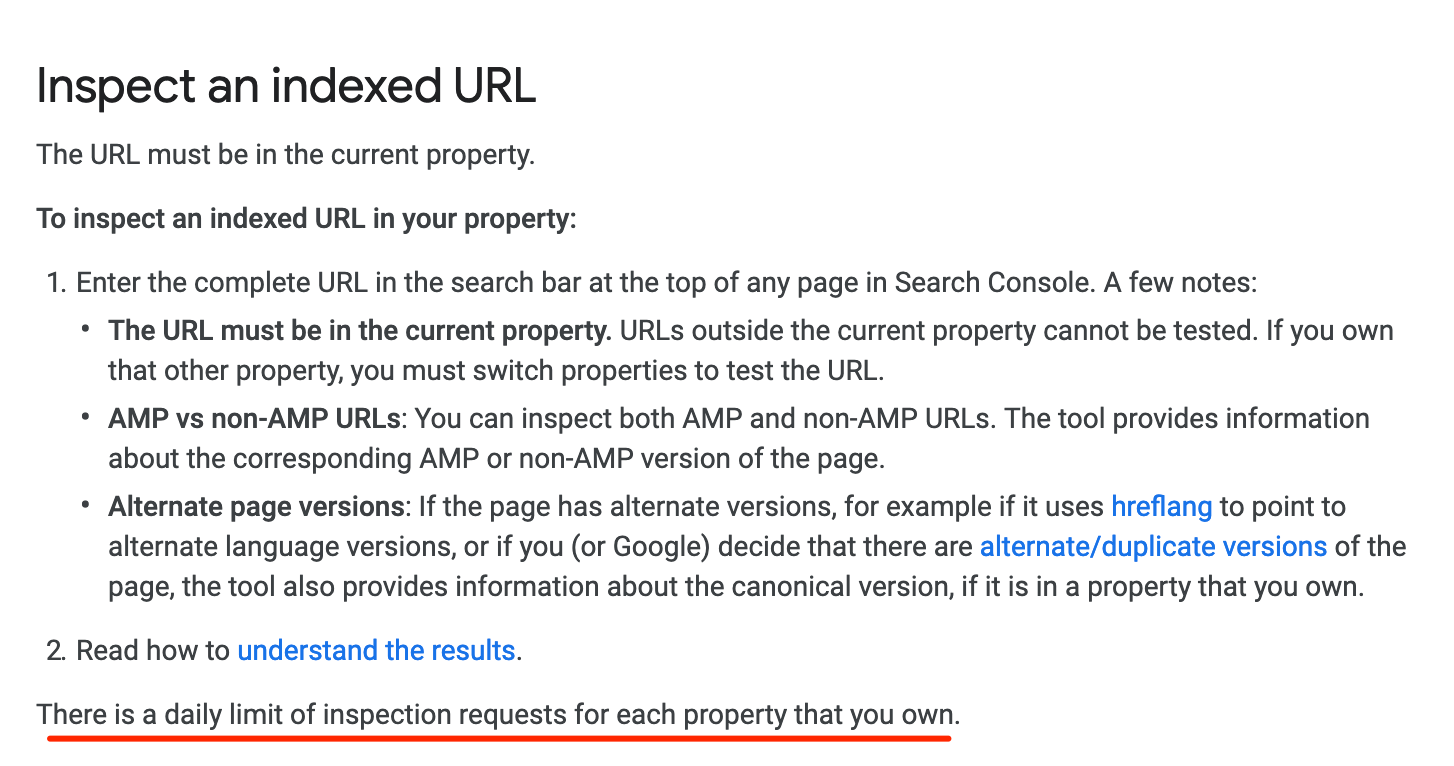
Since the Live Inspection Tool is far more about understanding and fixing problems with a page than the old ‘fetch as Google’ tool – which I, at least, mostly used to force a page to be indexed/re-crawled – it makes sense for the Live Inspection Tool to have a higher limit. Yet there’s no limit listed within the new tool. We turned to Google’s documentation and, honestly it could be more helpful:
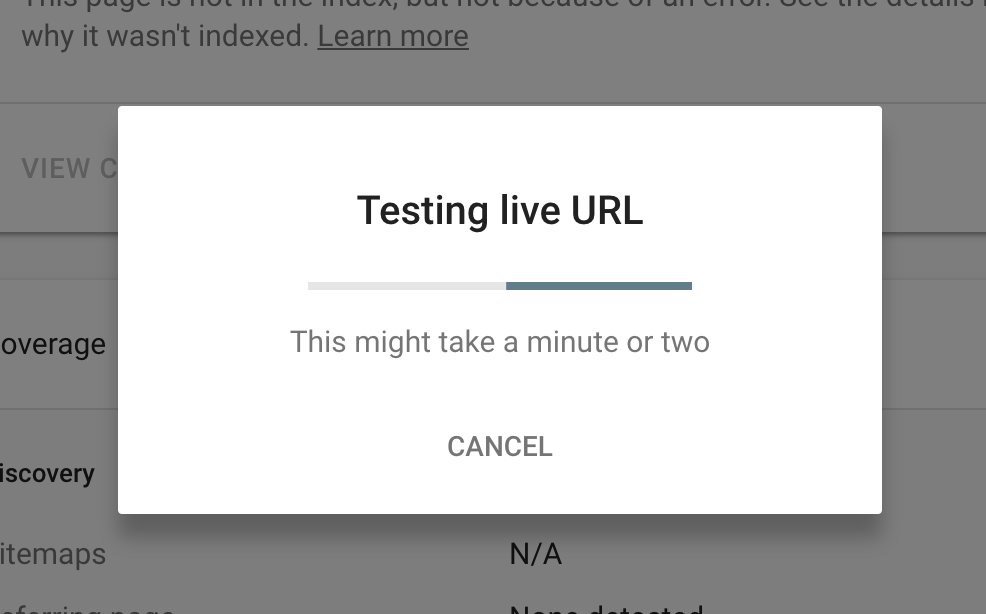
So, dear readers, we decided to put the Live Inspection Tool to the test with a methodology that can only describe as ‘basic’.
Methodology: We repeatedly mashed this button:
..until Google stopped showing us this:
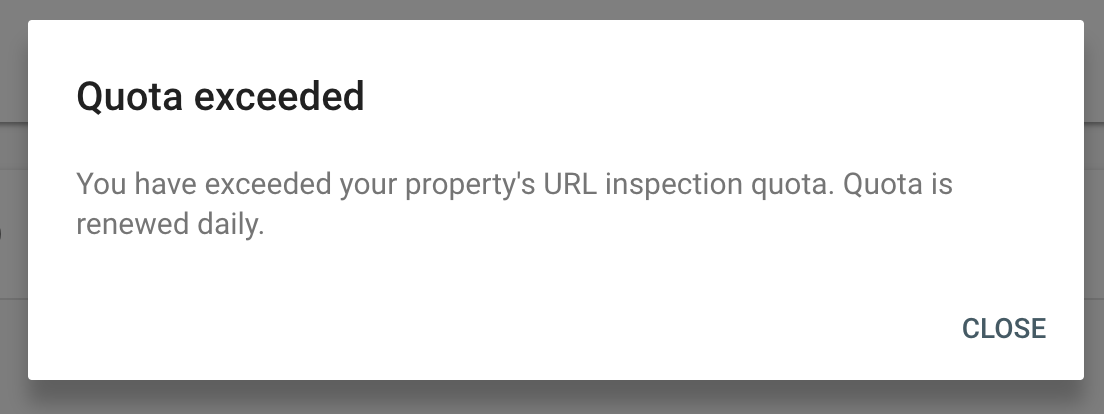
We quickly sailed past 10 attempts without a problem, on to 20, then 30. At 40 we wondered if there really was no limit, but, just as we were about to lose hope, on the 50th try:
tl:dr: The daily limit for Live URL Inspection is 50 requests.
How is knowing this actually useful?
Basic
If you’re planning a domain migration, you can add in to your migration plan a step to pick out your 50 most important URLs and manually request indexing on those pages on the day of the migration.
Intermediate
Taking that a step earlier, you could take the 100 most important pages and, once the redirects are in place, request indexing of 50 of the old URLs, through the old domain’s Search Console property, to pick up the redirects, whilst requesting indexing of the remaining 50 through the new domain’s Search Console property to quickly get those pages in the index.
Advanced
This is the ‘let’s try to break it’ option. 50 URLs is nowhere near Bing’s 10k URLs a day, but what if you could actually end up with more than 10k indexed through this technique?
Remember that you can register multiple properties for the same site. As a result there’s an interesting solution where you automatically register Search Console properties for each major folder on your site (up to Search Console’s limit of 400 in a single account) and then use the Live Inspection tool for 50 URLs per property – giving you up to 20k URLs a day – double Bing’s allowance! None of this would be particularly difficult using Selenium/Puppeteer; we’ve previously built out scripts to automatically mass-register Search Console properties for a client that was undergoing a HTTPS migration and had a couple of hundred properties they needed to move over, which went without a hitch. We didn’t use that script to mass request indexing, but, if you did, it could allow for a migration to occur extremely quickly. We don’t recommend doing this – I can’t imagine this is how Google wants you to use this tool, though equally I can’t think how they’d actively penalise you for doing this. Something, perhaps, to try out another day at your own risk. If you do, let me know how it works!
Does Google Crawl With HTTP2 Yet?
HTTP2 is a major revision to the HTTP protocol, agreed in 2015. At this stage it has pretty much universal support across web browsers. As HTTP2 supports multiplexing, server push, binary protocols, stream prioritisation and stateful header compression it is, in almost all instances, faster than HTTP1.1 and so implementing it can provide a relative ‘free’ speed boost to a site. But, how does Google handle HTTP2? We thought we’d find out.
The History
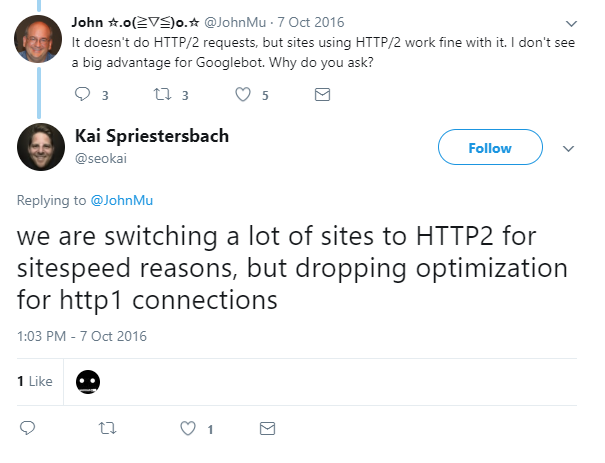
As HTTP2 is backwards compatible – if a browser doesn’t support HTTP2, HTTP1.1 is used instead – Google could read pages on HTTP2 sites the very first day the specification was built. Yet this backwards compatibility actually makes it difficult to tell whether Google is actually using HTTP2 or not. Mueller confirmed in 2016 that Googlebot wasn’t using HTTP2 yet:
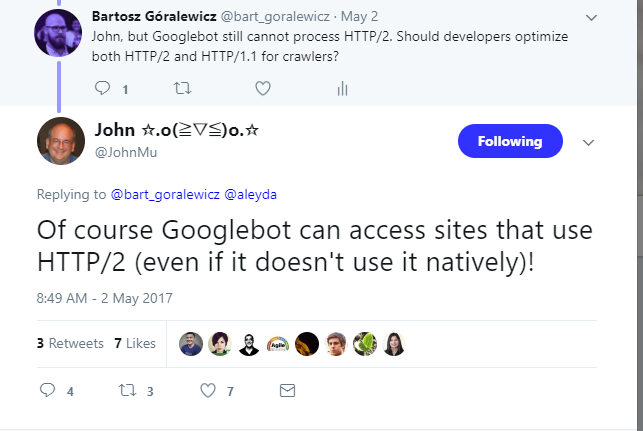
A year later, in 2017, Bartoz asked the same question and found that googlebot still wasn’t using HTTP2:
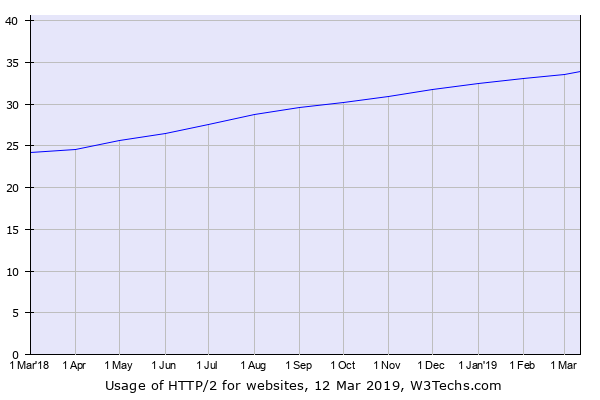
Two years later, much has changed, HTTP2 is now used by over a third of websites and that figure is growing by about 10% YoY:
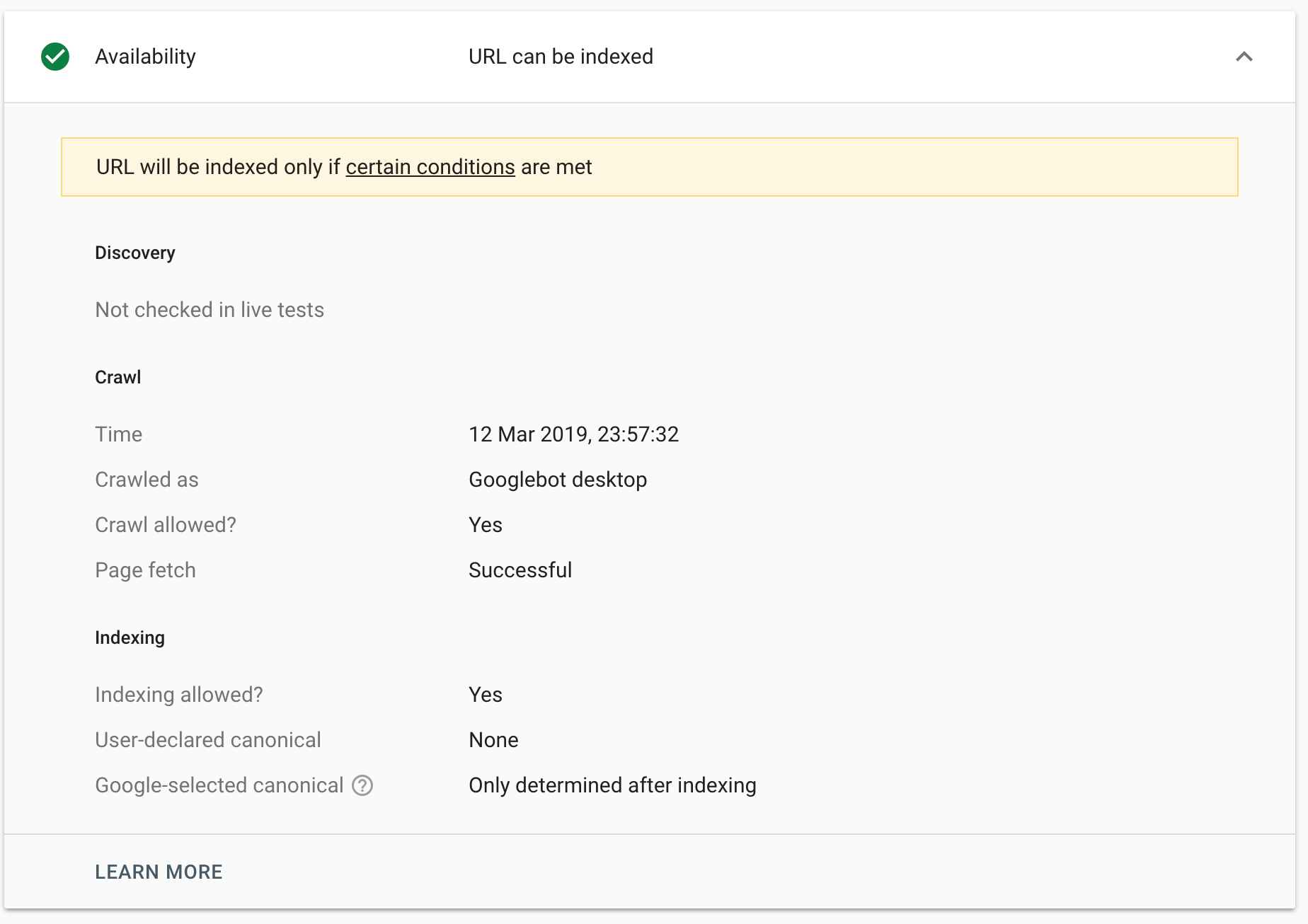
So, we thought we’d revisit the question. The setup was a little time consuming, but simple. We set up an Apache server with HTTPS and then HTTP2 support and made sure that Google could crawl the page normally:
Once we knew that was working, we edited the .htaccess file to block all http1.* traffic:
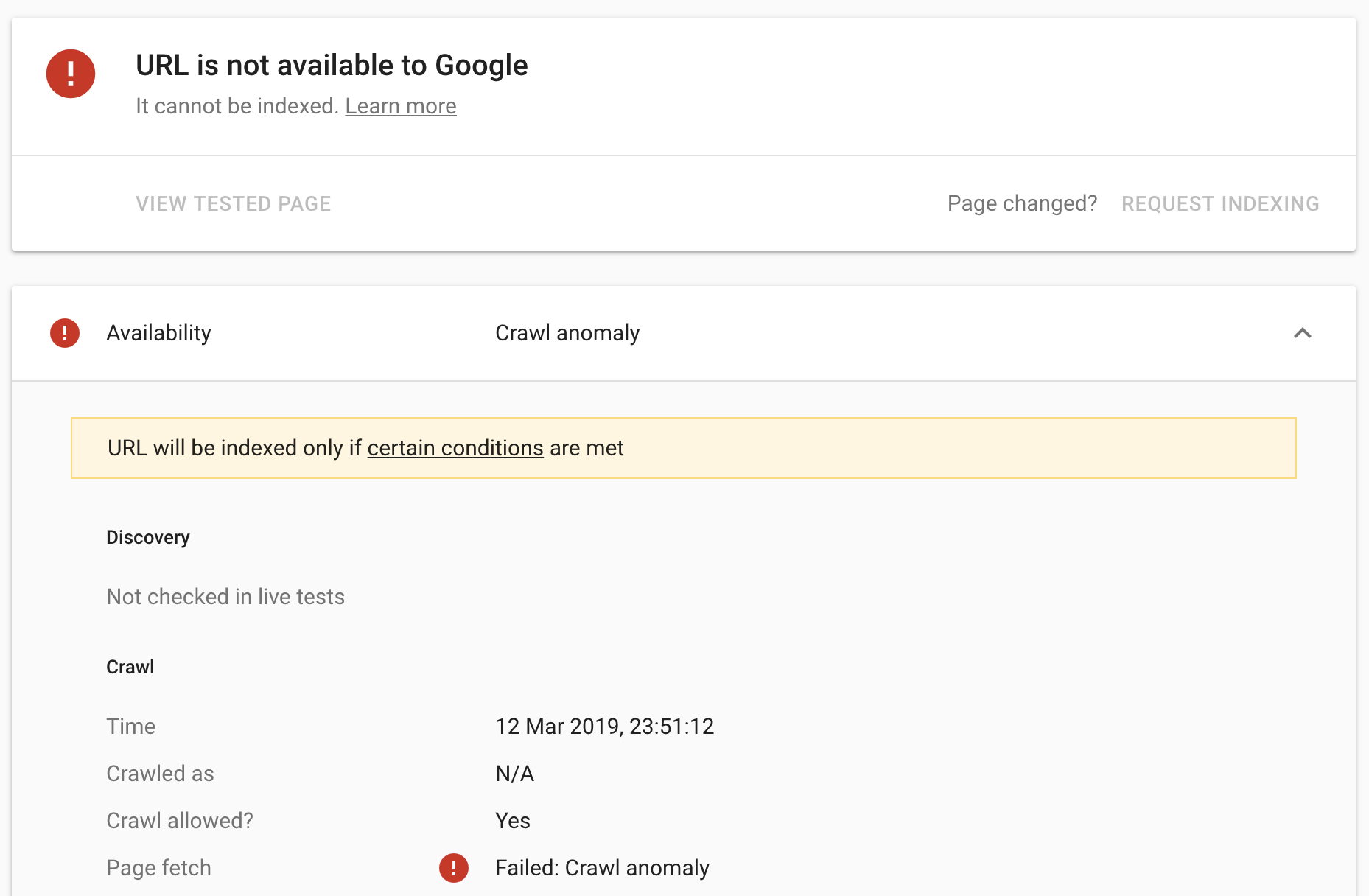
This time, when we requested Google recrawl the page, we received a crawl anomaly:
..and so no, googlebot still, somehow, does not support HTTP2. We wanted to see how Google would render the page as well, though. The assumption was that whilst Googlebot did not support HTTP2, WRS/Caffeine is based on Chrome 41, and Chrome 41 supports HTTP2, so, therefore, WRS should too. As a result, we changed the .htaccess file to, instead, redirect all HTTP 1.1 traffic to another test page:
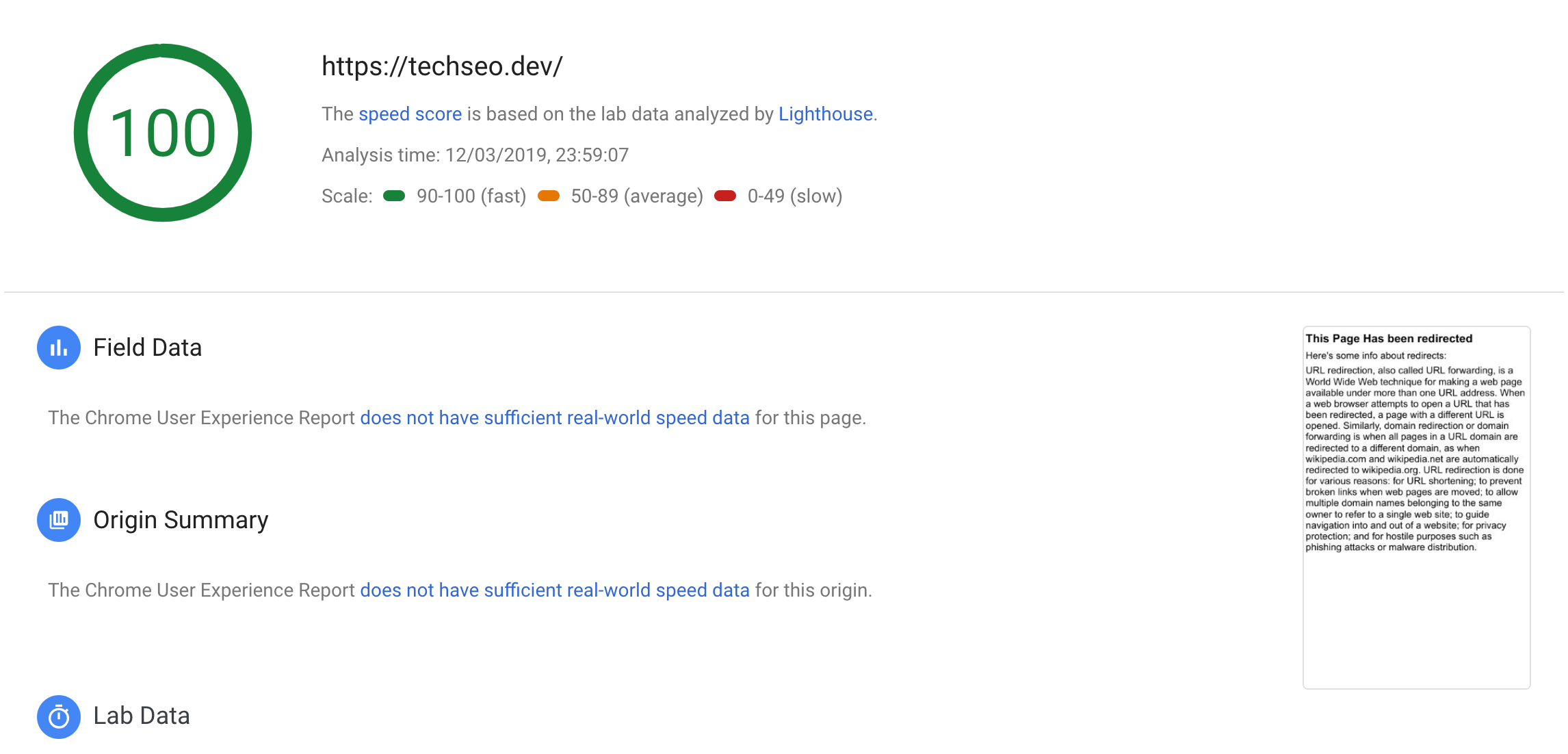
We then used PageSpeed insights to see how Google would render the page:
You may just about notice the preview in the bottom left is of a page with the headline ‘This page has been redirected’ – it loaded test.html rather than the homepage! So, for whatever reason, we must presume, that Google has hobbled WRS so that it always pulls the HTTP1.1 version of a page, which, in 99.999999% of cases would be identical to the HTTP2 version of the page.
Why does this matter?
This is interesting for two reasons:
1) It implies a very interesting way to cloak that I’ve not heard people talk about before. Internet Explorer has supported HTTP2 since 2013, whilst Firefox, Safari and Chrome have each had support since 2015. If you set certain content to only show for users with HTTP1.1 connections, as modern browsers all support HTTP2, effectively zero users would see it, but Google would. As with all cloaking, I don’t actually recommend this – and Google could add HTTP2 support at any time – but as ways of cloaking go, it would be difficult to detect as, effectively, nobody’s looking for it right now.
2) Due to HTTP2’s multiplexing abilities, there are several site speed recommendations that are different for HTTP1.1 than HTTP2 including, for example, spriting. Now that we know Google is not using HTTP2 even when your server supports it, by optimising your page for speed based on users using HTTP2 you might actually be slowing down the speed at which Google (still using HTTP1.1) crawls the page. Whilst Google’s tight-lipped on what mechanism, exactly, they use to measure site speed, the page load speed that googlebot itself finds will, of course, go to determining crawl budget. So if you’re really caring about crawl budget and are about to move to HTTP2 then you’ve got an interesting problem. This is simply one of those cases where what’s best for Google is not what’s best for the user. As such, there’s a reasonable case to be made that you shouldn’t prioritise, or potentially even bother implementing, any site speed changes that are different for HTTP1.1 than HTTP2 when moving to HTTP2 – at least until Google starts crawling with HTTP2 support… or you could combine both approaches and change the way you’re delivering CSS, icons etc based on the HTTP version that’s supported by the requested user, which is a lot of extra work, but technically optimal. That is, as we all know, the best kind of optimal.